Kubernetes important core concepts!
In this blog, I am going to cover a basic overview of the Kubernetes Cluster Architecture. We will drill down to each of these components, we will see roles & responsibility of these components.
The Kubernetes cluster consists of set of nodes which may be physical or virtual, they could be located on-premises or on public clouds that hosts applications in form of containers.
Kubernetes Architecture Core Concepts –
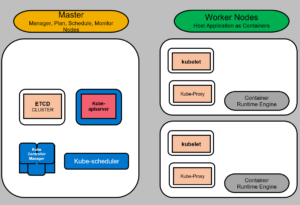
Now, somebody needs to load, control and manage the containers therefore there are control or master nodes in the cluster. The master nodes are responsible to manage the Kubernetes cluster by storing information of nodes, planing containers deployments etc.


Moving on, lets see ETCD.

There are many containers loaded on the Cluster, this information has to be stores somewhere. All of these information is stored in highly available database called ETCD in key/value pair format.
ETCD is a distributed reliable key-value store that is simple, secure & fast.
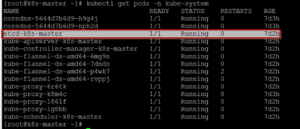
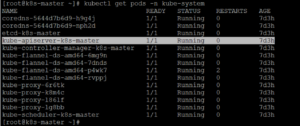
When you run ‘kubectl get’ command on Kubernetes cluster, ETCD present information regarding Nodes, Pods, Configs, Secrets, Account, Roles, Bindings etc..
Example of Key-Vale Store.
Name Age Location Grade
Dave 45 Sydney A
John 34 New York A
Every change you make to your cluster is updated to ETCD cluster.
Setup – Manual.
You can setup ETCD manually
wget -q –https-only \
“https://github.com/coreos/etcd/releases/download/v3.3.9/etcd-v3.3.9-linux-amd64.tar.gz”
Lets see the next core component called as Kube-API Server

Kube-apiserver is primary management components of Kubernetes. When you run kubectl command, the kubectl utility reach to kube-apiserver. The kube-apiserver authenticate & validate the request and then retrieves the data from ETCD cluster.
Since it’s an apiserver, you can essentially use API POST requests instead of kube command.
Now we will cover a bit of Kube Controller Manager.
![]()
In Kubernetes terms, a controller is a process that continuously monitors various components within the system and works towards bringing the whole system to a desired state.
For example, Node controller is responsible to monitor the status of nodes and responsible to keep application running. The Node Controller check the status of node every 5 seconds. If it stop receiving heartbeat from nodes, it wait for 40 seconds before marking the node as unreachable. It give 5 minutes to node comeback, if nodes doesn’t come back then it removes the pods from that node & re-provision to healthy nodes.
For instance, Replication controller monitor for the state of Pods, if pod is crashed or goes down, replication controller creates another replica of the POD as per the replica sets policy.
There are many other controllers in the cluster. e.g Namespace Controller, Endpoint Controller, Deployment Controller, Job controller, PV Protection controller etc..
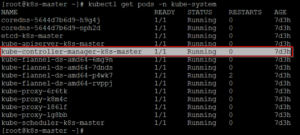
All these processes are packaged in a single process called as Kube-Controller-Manager
Next, we will cover a bit on Kube Scheduler

Kube scheduler is responsible for scheduling the Pods on nodes. It only decide which pod will go to which nodes, although it doesn’t place a Pod on node, that done by kubelet.
You may have Pods with different resource requirement, the scheduler finds a right Nodes for the pod.
Now, how does scheduler pick right node for the pod. The scheduler ranks the nodes to identify the best fit for a pod. It uses the Priority function to rank the nodes e.g calculate the free resources on nodes across the available nodes such as CPUs, Taints and Toleration, Affinity etc.

Finally. we will look at Kube-Proxy
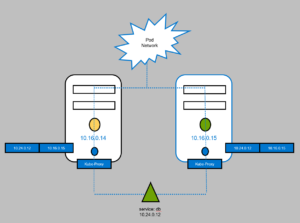
Every pod can reach any other pod in a cluster. This is accomplish using pod network, through this network they are able to communicate with each other.
for example, Web app deployed on one node and DB App deployed on another node. The Web app can reach to DB by simply using IP of the POD but there is no guarantee that IP of the DB POD will always remain the same. Therefore a better way for Web app to reach to DB app is by using a service.
So we create a service to expose the DB across the cluster. The service also gets an IP address, whenever a web pod try to reach the service using its IP, then service forward the traffic to backed pod that is DB pod.
The service never joins the Pod network then how the service gets its IP address? Service is a virtual component thus it uses kube-proxy. When a Node is deployed, there is kube-proxy process that runs on each node in Kubernetes cluster. Its job to look for new services and then if new service is discovered then it create a appropriate rule on each node to forward the traffic to those services to the backend Pods. In this case its create an IPtables rules on each nodes to forward traffic to services.
Hope you enjoyed this post, I’d be very grateful if you’d help sharing it on Social Media. Thank you!